|
|
本帖最后由 arition 于 2021-1-11 18:41 编辑
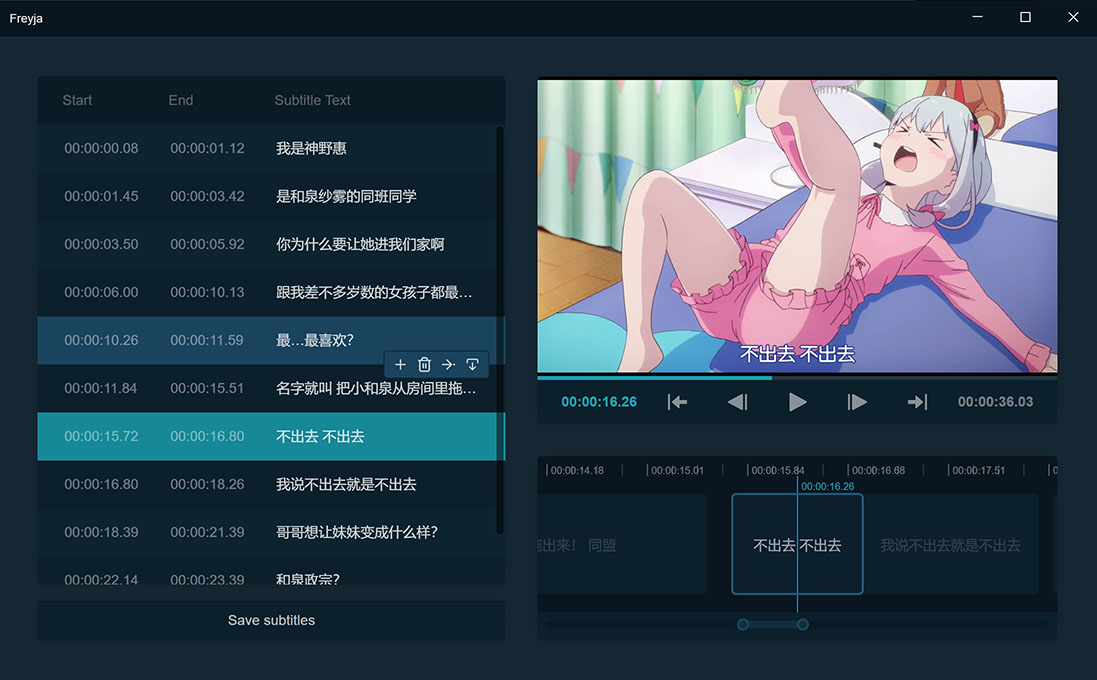
Freyja 是使用 PyTorch,Nodejs 和 Electron 编写的视频硬字幕提取工具,可以帮助手抄字幕用户更加方便的从视频中提取字幕。
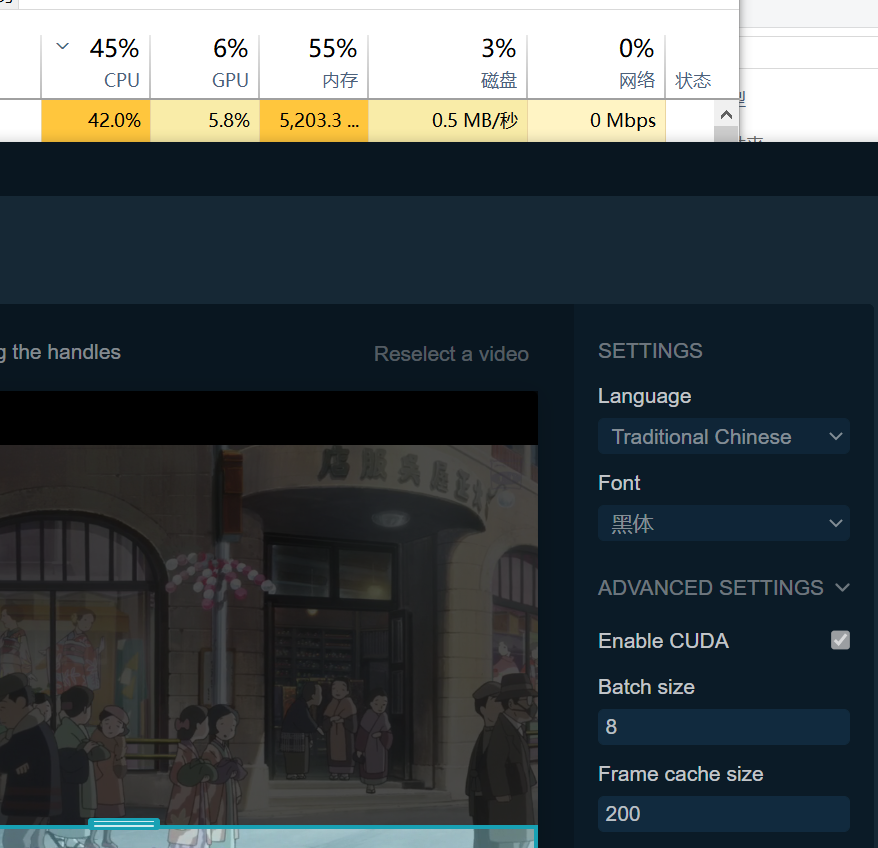
只需要简单的选择提取范围,工具就可以自动识别范围中的文字,无需传统手抄字幕软件复杂的调参操作。
目前仍然在 beta 测试中。基本功能都是可用的,但是可能会遇到 bug 或者随机崩溃等问题。如果你碰到了任何问题,请带上 log.log 文件在 Github issues (https://github.com/freyjaSubOCR/freyja-sub-ocr-electron/issues) 中报告。目前OCR只能识别一些常见的字幕组的字幕样式,如果遇到OCR识别准确率很差的情况,请提供一个可以让我下载视频的方法(链接,种子等)让我调试。
更新日志
2021/01/11 V0.4.0
新版使用了更新后的OCRV3模型。新的OCRV3模型相比旧的OCR模型来说运行速度更快,也更加准确。新模型使用的GPU内存较少,所以默认的批次大小从8个变更为32个。在Surface book 2笔记本上(i7-8650U,GTX 1060 Max-Q),新版本处理一段24分钟的视频只需要10分钟。
新版不需要以前的对象检测模型,也统一了CPU和GPU模型。
新的模型需要框选更准确的字幕边界,否则准确度会很差。
下一个版本主要会优化视频解码和播放。
系统要求
Freyja 需要 8GB 的内存。强烈推荐使用带 Nvidia 显卡的电脑,否则过程会非常缓慢。
使用
如果你使用的是 Windows,安装Visual C++ Redist 2019。如果你使用的是 MacOS 或 Linux ,确保已安装ffmpeg。
从https://github.com/freyjaSubOCR/freyja-sub-ocr-electron/releases下载最新版本的Freyja并将其解压缩。
从https://github.com/freyjaSubOCR/freyja-sub-ocr-model-zoo/releases中下载对应模型的所有txt和torchscript文件,并将这些文件放入<程序根目录>/models/文件夹。
运行freyja.exe。如果有 Nvidia 显卡,请启用Enable CUDA选项,否则禁用该选项。
已知的问题
视频播放很慢
目前的视频播放实现不是很可靠,会占用比较多的内存并且会有播放卡顿。在正式版推出之前会有新的视频播放实现。
无法使用 MacOS 和 Linux 版本
当前,底层的torch-js包存在一些问题。下一个测试版本预计会修复这个问题。
常见问题
视频播放没有声音。
目前视频播放器没有播放声音功能。
无法播放视频。
这个视频可能是vfr(可变帧率)视频,当前视频播放器不支持播放这类视频。一个比较简单的解决方法是使用ffmpeg进行转码,来把视频转换为恒定帧率视频:ffmpeg -i video.mkv video_transcoded.mkv。
无法使用GPU模型。
确认你有 Nvidia 的显卡。如果确实有 Nvidia 的显卡,请尝试更新驱动程序。
程序提示 "pyTorch backend crashed"。
检查一下 log.log 中的最后一条错误信息。
如果log中有 CUDA out of memory 的提示,说明显存不足。可以通过降低 batch size 来减少显存使用。如果降低 batch size 不起作用,说明你的显存太小,请换用CPU模型。
如果log显示其他错误,请尝试改变视频裁剪的大小然后重试。
碎碎念
这个项目本来是上学期图像识别课程的final project。当时只有非常简陋的代码,不过识别效果不错,所以用了暑假的时间写了一个正经的UI。暑假结束的时候其实已经基本写完了,不过开学了以后又忙了起来导致拖到现在才发布。接下来的计划主要是换掉这个写的非常烂的视频播放方法,换成最近新提出的模型,以及修bug。
|
评分
-
查看全部评分
|